![]()
|
|
|
|
|
|
디자인 뉴스 2 - 2004년 1월
실리콘 분할 (ASIC spin-offs seek success amid established alternatives)
글: Brian Dipert, 테크니컬 에디터
고객은 다양한 실리콘 리소스 가운데 선택을 하게 되며 벤더는 고객의 빌딩 블록 포트폴리오에 맞춰 이들의 요구를 충족시키고 있다.
자, 이제 여러분은 임베디드 컨트롤러, 주변기기 칩 등과 같은 기성품 ASSP(application-specific standard product)를 일괄 구매하고 이를 사용해 소프트웨어를 작성하면 경쟁업체의 제품들과 그다지 차별화된 설계를 제공하지 못할 것이라는 결론을 내렸다. 따라서, 여러분은 칩 레벨 설계에 착수하게 될 것이다. 실리콘 플랫폼 분야에서 쌍벽을 이루는 두 맞수와 이들의 상충 관계에 대해서는 지금까지도 다양한 업계 포럼에서 팽팽한 균형을 이루며 논쟁이 이뤄지고 있다. 이러한 정황에 생소한 독자들은 우선 아래 요약을 참고하기 바란다.
FPGA는 Xilinx의 최신 Spartan 3 제품군용 90nm 공정(참고 자료 1) 같은 딥 서브미크론 공정 덕분에 칩 당 게이트 수의 집적도가 갈수록 증가하고 있다. FPGA에서 제공하는 용량은 특히 설계에서 FPGA의 임베디드 메모리 배열, 확산형 아날로그 및 디지털 기능 블록(DLL 및 PLL 같은), 곱셈 누산기(multiply-accumulator), SERDES(serializer/deserializer) 회로, 고속 I/O 버퍼 등은 물론 이따금 CPU 코어와 관련 주변기기를 사용하는 경우에도 탁월한 성능을 발휘한다. 고객은 각자의 설계에 필요한 만큼만 FPGA를 주문할 수 있으며 공급업체에 NRE(nonrecurring-engineering) 비용을 지불할 필요도 없다. 벤더는 이미 칩의 로직, 메모리, 신호 배선 및 전력 플레인에 대한 레이아웃은 물론 디버깅까지 마친 상태이다.
일단 설계가 완료되면 단시간 내에 완성된 칩을 얻을 수 있다. 아울러 보다 일반적인 면을 따져보면, 설계 개발 및 디버깅에 사용한 툴의 비용이 ASIC 툴보다 훨씬 더 저렴하다(그러나 현재 2만 5,000 달러 정도인 Hier Design의 PlanAhead가 업계를 주도하게 된다면 FPGA 툴셋의 평균 가격은 상승할 것이다.) 그렇지만 FPGA는 집적도에 상관 없이 필적할 만한 공정을 바탕으로 하는 표준 셀 ASIC에 비해 효율이 한 두 등급 떨어진다. 또한 실리콘을 많이 차지하는 셀 당 6개의 트랜지스터 SRAM LUT(look-up-table) 및 구성 요소 기술에 기반을 둔 FPGA는 ASIC에 비해 전력 소모량이 상당히 크다.
안타깝게도 ASIC의 이점은 그에 상응하는 일련의 단점들을 수반한다. 칩이 무어의 법칙 리쏘그래피 경로를 따라 하락함으로 인해 NRE 비용, 최소 주문량, 시트 당 개발 툴 슈트 비용이 급등하고 있다(그림 1). ASIC의 최소 주문량은 벤더가 생산 라인을 줄여 수익을 유지할 수 있는 특정 고객 웨이퍼의 최소 수량을 나타낸다. 칩 다이가 커질수록 필요한 최소 주문량은 줄어들게 되므로 보다 작은 공정 리쏘그래피와 넓은 웨이퍼로 이전한 현상이 최소 수량 요건을 이처럼 크게 증가시킨 이유도 확연히 알 수 있을 것이다.
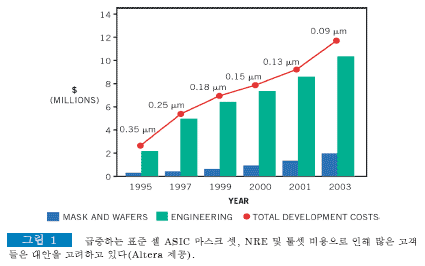
공급 전력의 약화, 신호 커플링을 비롯해 그 밖의 딥 서브미크론 라우팅 효과로 인해 발생하는 특이한 버그를 추적 및 수정해야 하는 시기가 라우팅 위주의 타이밍 클로저 노력과 결합되어 표준 셀 ASIC 개발 주기가 늘어나고 있다. 설계가 완료되었다고 생각되는 순간에도 칩이 돌아오기 전까지는 지루한 제작, 테스트 및 패키징 단계를 기다려야 하며, 칩이 제대로 동작하지 않거나 신속하게 변화하는 시장의 요구를 더 이상 충족시키지 못하면 비용이 증가하고 지연이 발생하게 된다. 표준 셀 ASIC을 이용한 설계는 많은 시간과 노력 그리고 비용이 필요한데, 최근 애널리스트들의 보고서 내용에 따르면 이러한 요인들은 업계가 FPGA로 급격히 선회하고 있는 이유 중 하나라고 한다. 그러나 설계 게이트 수나 칩 수량이 수십만 개에 달하거나 성능 위주 또는 전력 요구조건이 엄격한 설계에서는 표준 셀 ASIC이 여전히 유일한 수단이다.
기존 솔루션
과연 그런 것일까? 이 질문에 답하기 위해 우선 FPGA와 ASIC의 근본적인 실리콘 빌딩 블록인 로직 셀과 배선 구조를 비교해 보자. FPGA의 로직 셀은 거친(coarse-grained) 특성이 있고 멀티플렉서 집합 및 개별 로직 게이트에서 하나 이상의 LUT에 이르기까지 다양할 뿐 아니라 대개 플립플롭을 통해 보충된다. 현재 업계에서 가장 미세한 로직 블록을 제공하는 제품은 Actel의 ProASIC FPGA이다. FPGA 벤더들은 자사 소자의 내부 로직 블록 배선을 설계하므로 사용자가 구성해야 하는 배선층의 수를 최소화하지만, 그에 따라 설계 컴파일레이션과 배치 및 배선 소프트웨어는 로직 블록을 효율적으로 사용해야 하는 근원적인 난제에 빠지게 된다. 칩은 대부분 프로그래밍되지 않은 로직 간 블록 배선 자원과 함께 제공되므로 안티퓨즈(antifuse) 및 플래시 기반 칩에서는 시스템 전력 상승 전에 구성하고, 설계에서 지원할 경우 SRAM 기반 FPGA에서는 전력 상승 시와 그 이후에 구성한다.
표준 셀 ASIC의 로직 블록은 FPGA의 로직 블록보다 훨씬 미세하다. "표준 셀"이라는 명칭이 의미하듯 이 로직 블록은 트랜지스터 및 기타 온칩 구조를 위해 일정한 크기의 면적을 사용한다. (이러한 균질성은 완전 주문형 칩과 구별되는 중요한 특징이다). 그러나, "특정 애플리케이션"이라는 말이 의미하듯 소자의 클럭, 전력, 신호 배선에 따른 배치는 사용자의 구현에 따라 다르다. 그 결과 모든 칩의 금속 및 다중 실리콘 층이 고객별로 독특하며 벤더는 소자를 선적하기 전에 미리 배선을 구성하므로 시스템 제작과 그에 수반되는 동작을 진행하는 동안 하드웨어 주문화 기능을 누릴 수 없다. 이 경우 개발 소프트웨어는 거친 FPGA의 경우처럼 각 로직 블록 내에서 설계를 효율적으로 구현하는 데 초점을 맞추는 것이 아니라 블록을 효율적으로 상호 연결하는 데 중점을 두게 된다.
또 다른 ASIC 범주인 게이트 배열은 전통적으로 FPGA와 표준 셀 ASIC 사이에 위치해 왔다. 게이트 배열의 배선 그물(routing mesh)는 FPGA와 마찬가지로 일반적이고 사전에 결정되어 있다. 또한 표준 셀처럼 이 배선 그물의 특정 설계 구성도 칩 제작의 최종 몇 단계에서 일어나므로 벤더들은 이따금 미세한 로직 셀 층을 "2 입력 NAND 게이트의 바다"로 불렀다. 최근 몇 년간 게이트 배열의 사용이 크게 줄어들어 FPGA가 영역을 잠식해 들어옴에 따라 한 가지도 잘하는 게 없는 팔방미인의 희생물이 되어가는 현상이 갈수록 뚜렷해지고 있다. 게이트 배열의 가용량 주문 소요 시간은 표준 셀에서 대용량 FPGA 사업을 따낼 수 있는 표준 셀만큼 빠르지 못할 뿐 아니라, 많은 표준 셀 기회를 떠맡기에도 성능 및 실리콘 효율이 너무 빈약했다.
마스크 프로그래머블FPGA
사업 부진에 놀란 일부 ASIC 공급업체들은 과거 게이트 배열 시절 구조화된 ASIC을 따라잡기 위해 배운 교훈이 담긴 FPGA 서적에서 약간의 지식을 조합했다. 또한 일부에서는 이러한 접근 방식을 모듈식 배열 또는 구조화된 배열로 부른다. 벤더 간 현저한 기술력의 차이가 존재하지만 간단히 말해 구조화된 ASIC은 소위 FPGA류의 거친 로직 셀을 갖춘 게이트 배열의 파생물이므로 사용자가 구성할 수 있는 금속 및 비아(via) 층이 줄어든다. 벤더는 클럭 트리와 전력 플레인 배선을 처리한다. 소프트웨어 프로그래밍 초기에는 마이크로프로세서의 처리 속도가 느렸고 메모리 가격은 비싸서 낮은 레벨의 고효율 어셈블리 언어나 이보다도 낮은 레벨의 기계 코드가 주를 이루었다는 사실에서 유추하는 것이 구조화된 ASIC의 현 위치를 이해하는 데 도움이 될지 모른다.

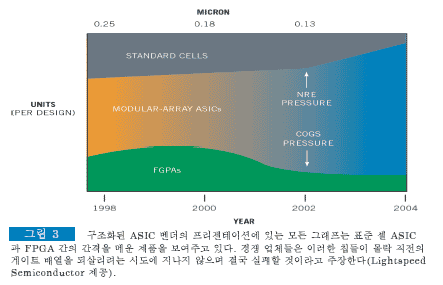
CPU가 점점 빨라지고 메모리 가격이 내려감에 따라 더 높은 레벨의 소프트웨어 언어가 등장하기 시작했다. 이러한 언어들은 리소스 사용 효율성이 다소 떨어지지만 이제 효율성만 갖고 모든 게 다 되는 시기는 지났다. 하지만 출시 시간의 중요성은 갈수록 높아지고 있으므로 이런 관점에서 보면 레벨이 높은 언어를 선택하는 편이 훨씬 낫다. 이와 비슷한 이유로 VHDL과 Verilog은 회로를 칩에 끼워 넣는 하드웨어 엔지니어들이 더 많은 시간이 걸리는 회로도 기법을 제치고 갈수록 많이 선택하는 설계 입력 방식이다. 구조화된 ASIC 벤더들은 비록 표준 셀보다 효율이 떨어지고 FPGA에 비해 출시 시간이 길더라도 경쟁 제품의 단점을 어느 한쪽도 모두 나타내지 않는 실리콘 플랫폼 시장이 출현할 것이라는 기대에 성패를 걸고 있다(그림 3).
높은 비율의 칩 마스크?형편이 좋을 경우에는 가장 비싼 마스크인?는 여러 고객의 설계에 보편적으로 사용되므로 고객 당 NRE 비용과 소요 시간이 줄어들 뿐 아니라 결과적으로 생성되는 플랫폼을 발전하는 업계 표준을 비롯해 최소 수준으로 변경된 하드웨어가 들어 있는 부산물 칩에 보다 쉽게 적응시킬 수 있다(그림 4).

AMI Semiconductor, Chip Express, Faraday Technology, Fujitsu, Lightspeed Semiconductor, NEC, ViASIC 등 업체들은 현재 저마다 구조화된 ASIC 웨어의 홍보에 열을 올리고 있다. 이 가운데 AMI는 현재 광범위한 실리콘 공급업체가 아닌 유일한 벤더로 활동하며 FPGA 로의 변환 틈새에 끼어 들고 있지만, 과거의 게이트 배열 플랫폼 대신 구조화된 ASIC 토대를 사용하고 있다. 이와 반대로 Lightspeed Semiconductor는 기존의 ASIC에만 주력하기 위해 Xilinx의 FPGA 같은 비용 절감형 시장으로의 확장에서 손을 뗀 상태다(참고 자료 2). Chip Express의 구조화된 ASIC은 다양한 대안 중에서 가장 세밀한 로직 블록을 사용하는 것으로 알려져 있는데, 이 업체의 소자에는 설계에 따라 로직 모듈 당 세 개 내지 네 개의 게이트가 들어간다고 한다. 다른 벤더들의 로직 블록은 대부분 저마다 20~40 게이트에 상당하는 설계를 구현한다(그림 5).

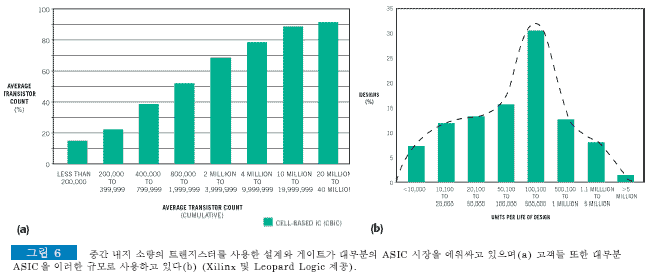
구조화된 ASIC 공급업체들은 다양한 공정의 혼합을 바탕으로 칩을 생산하는데, 이 같은 다양성은 자사의 제품 제작 방식이 잠재 고객 기반 위에서 독점적인 지위를 선점하도록 하기 위한 각 벤더의 노력을 보여 주는 사례이기도 하다. 벤더와 파운드리들은 이미 트레일링 에지(trailing-edge)의 잘 알려지고 수율이 높은 0.18, 0.25 및 0.35 미크론 공정 구축에 사용한 제작 시설과 장비를 양도했다. 여기에서 구현할 수 있는 설계의 크기에는 상한선이 있지만 관련 벤더들은 고객이 10만 개 이하에서는 전체 ASIC 설계의 절반을 사용한다는 데이터와 함께 ASIC 설계의 게이트 수가 대부분 백만 개에 미치지 못한다는 애널리스트 보고서의 내용을 언급했다(그림 6).
스펙트럼의 다른 쪽 끝에는 Fujitsu와 NEC 같은 업체들이 있다. Fujitsu는 현재 0.11 미크론 공정에서 구조화된 ASIC을 제작하고 있으며 2004년에는 0.09 미크론 공정을 도입할 계획이다. NEC는 내년 하반기경에 90 nm 공정이 생산 체제에 들어갈 것으로 예상하고 있다. 공정을 설계에 맞추는 일은 설계의 I/O 버퍼 수를 이해하는 일과 관련되기도 한 섬세한 조정 작업으로 벤더와 고객이 최종적으로 바라는 것은 다이에 미사용된 부분이 들어 있어 최소 크기가 제한된 I/O 링 내에 실리콘 소모 영역이 남아 있는 것이다. 또한 복잡한 패키지로 인한 비용의 상승으로 패키지 내의 실리콘 비용도 그에 비례해 무의미해지고 있다(참고 자료 3).
구조화된 ASIC 공급업체들은 설계 핸드오프(handoff)에서 최초 샘플이 나오기까지 수개월이 걸리는 표준 셀의 소요 시간이 단 몇 주로 줄어들었다고 주장한다. 이러한 지연은 FPGA가 배치 및 배선된 네트리스트에서 실리콘으로 전달하는 몇 초에서 몇 분의 지연 시간과 크게 다르지 않지만, ASIC 지지자들은 이러한 비교가 사과와 오렌지를 비교하는 것처럼 비상식적이라고 평한다. ASIC 지지자들은 FPGA와 이를 사용한 설계가 복잡해짐에 따라 엔지니어들이 면적("적합할 것인가?")과 타이밍("충분한 속도로 동작할 것인가?") 클로저에 도달하는 데 많은 시간을 소모하고 있음을 지적한다. ASIC은 본질적으로 FPGA보다 빠른 설계이기 때문에 시뮬레이션과 재설계 시간을 단축할 수 있으므로 구조화된 ASIC을 사용하면 FPGA의 경우보다 전체 개발 주기가 짧아질 수도 있다.
하드웨어 주문형 ASSP
구조화된 ASIC 공급업체들이 성능 위주 회로의 속도를 극대화하고 면적 및 전력 개선 같은 그 밖의 효율을 구현하는 방법은 이러한 회로들을 일반적인 로직 구조 대신 칩의 확산된 부분에 집어 넣는 것이다. 예를 들어 Fujitsu는 자사의 확산형 임베디드 플립플롭이 다른 접근 방식에 비해 전력 분산을 절반으로 줄이고 게이트 사용량을 1.5~2배로 정도 늘린다고 주장한다. Lightspeed는 100%의 고착 고장 범위를 보장하고 딥 서브미크론 유도 지연 고장을 파악하기 위해 AutoTest와 AutoBIST를 자사의 Modular Array ASIC 내의 속도 검사 회로에 집어 넣었다. 여기에 언급한 모든 구조화된 ASIC 공급업체들은 확산된 임베디드 SRAM 블록을 제공하며, 이들 중 여러 업체들은 설계상 필요할 경우 타이밍 회로, 고속 직렬 및 병렬 I/O 버퍼를 비롯해 그 밖의 아날로그 구조와 영역, 전력 및 성능 위주의 구조를 통합할 수 있다.
LSI Logic은 플랫폼 ASIC으로 현재 0.11 및 0.18 미크론 공정에서 제작 중인 자사의 RapidChip을 사용하여 확산형 회로의 성능을 극대화하고 있다. LSI Logic은 RapidChip이 몇 년 전의 황금기를 다시 누릴 수 있을 것으로 기대하고 있는데, 당시에는 고객의 주문이 쏟아져 하루 평균 세 개의 설계를 진행했었다. 현재는 3일에 한 번 꼴로 새로운 설계를 수행하고 있다. LSI Logic은 확산형 아날로그, 디지털 및 SRAM 배열, 메모리 자원을 특정 애플리케이션에 맞게 혼합하는 것에서 출발했으며, 이러한 메모리 자원은 SRAM 배열, 마이크로프로세서 코어, PLL을 비롯해 10 기가비트 이더넷, 광 채널, SATA 등의 SERDES 기반의 인터페이스 같이 다이에서 많은 비중을 차지하는 것들이다. 또한 한 배열 내지는 다중 배열의 온칩 내장 게이트 배열 ASIC을 사용하여 이처럼 할당된 기능을 보완하고 있으며, 제작된 칩에 RapidSlice라는 이름을 붙였다. LSI Logic의 Extreme 제품군은 광범위한 확산형 코어를 포함하는 주문형 애플리케이션으로 적분기(Integrator) 제품이 가장 보편적이다.
미세 게이트 배열 로직 셀을 나타내는 RapidChip의 부분은 5개나 되는 금속 층을 사용자 주문 방식으로 제작할 수 있다. 범용 RapidSlice에서 주문형 RapidChip으로 전환하는 일은 게이트 배열의 파티션 밀집도와 관련이 있으며 고객이 설계한 고유 회로와 LSI Logic의 CoreWare 라이브러리에서 라이선스를 제공한 코어를 모두 사용할 수 있다. 이 코어들은 "소프트," "하드," 또는 "펌" IP(intellectual property)로 구성될 수 있는데, 소프트 IP는 레이아웃 유연성이 가장 뛰어나지만 성능이 가장 떨어지는 단점이 있다. 배치 및 배선이 사전에 정의되어 있으며 사전 제작되는 Diffused RapidReady 코어와 구분하기 위해 자체적으로 Hard RapidReady IP로 불리는 하드 IP는 속도 대비 적응성 스펙트럼의 반대편 끝에 놓여 있다. 펌 IP는 사전에 배치되지만 배선되지는 않으므로 다른 변형들 간의 중간 단계에 놓여 있다. LSI Logic은 RapidChip에서 자사의 IP 호환 표준 셀 ASIC에 이르기까지 간단한 비용 절감 방법이 숨어 있다고 주장한다.
RapidChip 프로그램은 구현 방정식의 실리콘 부분 뿐 아니라 특히 첨단 기술이 침체에 빠진 시대에 문제가 되는 개발 툴 비용에도 초점을 맞추고 있다. RapidChip 라이브러리는 고객이 이미 보유하고 있는 모든 고가의 표준 셀 ASIC 툴 수트를 연결할 계획이며 다른 ASIC 벤더들의 라이브러리에서도 이러한 방식으로 연구하고 있다(참고 자료 4). LSI Logic은 또한 Synplicity 및 Tera Systems와 물리적 합성, RTL-규칙 검사 및 플래닝 능력을 통합한 포괄적 툴셋 RapidWork의 공급 계약을 체결했으며 라이선스 비용은 6개월에 2만 달러이다. FPGA 업계에서 오랫동안 설계 소프트웨어 부문을 지배해 온 Synplicity는 보다 많은 수의 설계 시트를 위해 수익성이 낮은 설계 시트 당 수익 마진을 교환하는 비즈니스 접근 방식에 매우 익숙해 있다. 전통적으로 ASIC에 전념해 온 EDA 공급업체들은 이러한 전환을 어렵게 생각할 것이며 Synplicity는 ASIC 시장에서의 이러한 우회적인 시도를 통해 자사의 Synplify ASIC 제품이 지금까지 이루어온 것보다 더 큰 성공을 거둘 것으로 기대하고 있다. Synplicity는 또한 Chip Express, Lightspeed, NEC 등과 업무 제휴를 체결했다고 발표했다.
경쟁 업체들은 구조화된 ASIC 벤더들의 주장을 비웃고 있다. 예컨대 Actel과 QuickLogic은 자사의 안티퓨즈 FPGA가 이와 유사한 거친 구조의 ASIC에 비해 훨씬 우수한 설계 및 제작상의 유연성을 제공할 뿐 아니라 집적도와 성능이 뛰어나다고 주장하고 있다. Actel의 Barry Marsh 마케팅 부사장 역시 문화적 요인이 구조화된 ASIC 움직임에 영향을 미친다고 생각한다. 아시아 지역 벤더들은 "관계"라는 요인으로 인해 통상적으로는 받아들이지 않는 작은 규모의 사업에 집착하고 있으며, 구조화된 ASIC은 이러한 사업을 수익을 낼 수 있는 수준으로 이끄는 수단이 된다고 그는 지적했다.
IBM이나 Toshiba 같이 구조화된 ASIC 프로그램이 없거나 적어도 공개적으로 프로그램을 발표하지 않은 구조화된 ASIC 공급업체들 역시 신규 업체들이 원대한 목표를 달성할 수 없을 것이라고 주장한다. Toshiba는 FPGA와 표준 셀 ASIC이 모두 업계에서 자리를 잡았기 때문에 비용, 성능, 전력 소모, 출시 시간 또는 그 밖의 모든 요인으로 인한 둘 사이의 갭은 구조화된 ASIC 공급업체들이 오랫동안 생존하기에는 너무 작은 것으로 믿고 있다. Toshiba는 최근 수년 간 IP 라이브러리, 검증 방법 및 백엔드 툴 부문에 많은 투자를 해왔으며 목표는 핸드오프와 제작 간의 간격을 6개월 이내로 줄이는 것이라고 밝혔다.
Toshiba는 로직 버그가 아닌 배선 오류에서 대부분의 설계 리스핀이 이뤄지므로 자사의 제품 같은 하이브리드 표준 셀 플러스 게이트 배열 플랫폼(hybrid standard-cell-plus-gate-array platform)은 대다수 고객의 요구를 충족시킬 것으로 주장하고 있다. Xilinx 역시 구조화된 ASIC 벤더의 전망에 대해 비관적으로 보고 있다. Xilinx는 자사의 FPGA를 첨단 리쏘그래피로 이동함으로써 트레일링 에지 공정(trailing-edge-process) 기반의 구조화된 ASIC이 가질 수 있는 모든 장점들을 부정할 수 있다고 믿고 있다(그림 7).

다양한 반응
Xilinx는 또한 LSI Logic의 RapidChip이 확산형 PowerPC 코어를 비롯한 그 밖의 회로를 포함하고 있으며 보다 유연한 SRAM 기반 프로그래머블 로직을 위해 RapidChip의 마스크 프로그래머블 파티션을 교환한 점에서 자사의Virtex-II Pro 플랫폼과 유사하지 않은가 하는 의심을 내비쳤다. 그 밖의 FPGA를 포함하는 하이브리드 칩의 예로는 Altera의 Excalibur 제품 라인, Atmel의 FPSLIC(field-programmable system-level IC) 칩, QuickLogic의 Embedded Standard Product 및 Triscend의 Configurable Systems on Chip을 들 수 있다(참고 자료 5 및 6). IBM은 Xilinx와 제휴하여 Xilinx의 FPGA 기술을 사용할 수 있게 되었는데, IBM측에서는 아직 실질적인 결과를 발표하지 않았지만 업계 전문가들은 IBM이 곧 임베디드 FPGA 코어를 자사의 표준 셀 ASIC에 탑재할 것으로 믿고 있다.
ASIC 분야에서 Altera의 성공을 관측 및 분석해보면 흥미로운 사실을 알 수 있다. 몇 달 전까지만 해도 Altera는 주요 경쟁 업체인 Xilinx와 마찬가지로 ASIC 기술을 강도 높게 비판해 왔다. 그러나 최근 Altera는 최신 Stratix FPGA를 겨냥한 HardCopy FPGA 변환 플랫폼을 출시했다. 연 2000 달러에 사용할 수 있는 자매품 Quartus II Version 3 설계 소프트웨어는 설계를 HardCopy로 직접 컴파일할 수 있어 중간 Stratix 단계를 뛰어 넘었고 사실상 Altera는 구조화된 ASIC 공급업체로 등극하게 되었다. Altera는 HardCopy 제품이 연간 5,000대 이상 판매될 것으로 전망하며 이러한 수치는 고객 및 소자의 변화에 따라 달라질 수 있다고 Tim Colleran 마케팅 담당 부사장은 말했다. NRE 비용은 약 20만 달러에 이를 것이며 고객, 소자, 수량에 따라 유사하게 조정될 것이라고 그는 덧붙였다. 이 업체에 따르면 HardCopy 샘플은 약 8주 후에 선보일 수 있으며 제품 제작에는 약 18주가 걸린다고 한다. 고객은 HardCopy 칩을 받을 때까지 계속 FPGA를 사용할 수 있다. 하지만 중요한 점은 HardCopy 디바이스는 비록 일부 경우에서 FPGA 제품에 비해 온칩 메모리의 용량이 적지만 보기 드문 최적화된 가격의 패키징 옵션이라는 것이다.
Altera는 HardCopy 칩이 FPGA에 비해 평균 50% 정도 빠르고 70% 작으며 전력 소모량은 40% 적은 것으로 분석했다. 이 같은 성능 향상은 과거 LSI Logic의 부사장이었던 Altera의 신임 CEO John Daane의 영향 때문일 수도 있다. Xilinx는 HardCopy의 중요성을 잊은 채 자사의 비용 절감 프로그램인 EasyPath를 내놓았다. 얼마 전 Xilinx는 HardCopy와 유사한 HardWire를 내놓았으나 자사의 R&D 연구소에서 이를 제작할 것이라고 발표하지는 않았다. EasyPath의 실리콘 기반은 일반 FPGA와 동일하나 Xilinx는 일반적으로 높은 수율을 나타내는 특정 고객의 흐름에서 이에 대한 검사를 실시했다. 이처럼 변경된 흐름은 설계에서 사용하지 않는 칩의 비동작 부분을 더 이상 화면에 표시하지 않고, 대개 엄격한 교류 및 직류 규격을 설계상의 필요에 따라 적절히 완화한 것이다.
신규 FPGA 업체인 Leopard Logic 역시 ASIC-플러스-프로그래머블-로직 하이브리드의 미래를 긍정적으로 보고 있다. Leopard Logic은 몇 년 전 설립 당시만 해도 임베디드 FPGA 기술을 ASIC 벤더를 비롯해 파운드리와 이들의 최종 고객에게 알리는 업체였다. Actel, Adaptive Silicon 및 임베디드 FPGA 분야에 뛰어든 다른 업체들과 마찬가지로 Leopard Logic은 사업 초기에 미약한 성공을 거뒀다. 이 회사의 경영진은 모험을 싫어하는 벤처 투자자들이 IP 업체에 대한 투자를 중단했을 때 심각한 자금난 겪었다고 밝힌 바 있다. Leopard Logic은 완전한 ASIIC 공급업체가 되어 자사의 임베디드 FPGA 기술을 통합했으며, 연말까지 시제품을 내놓을 계획이다.
요약 내용
참고 자료
추가 정보
본 기사에 나온 제품에 대한 정보가 필요할 경우에는 아래의 업체에 문의하시면 됩니다.
저자
테크니컬 에디터인 Brian Dipert는 실리콘 빌딩 블록 옵션의 전분야에 대해 수많은 실무 경력을 갖고 있으며, 앞으로도 다양한 저술 활동을 계획하고 있다. 연락처는 전화 1-916-454-5242, 팩스: 1-617-558-4470, 이메일 bdipert@edn.com이며, www.bdipert.com에 그의 홈 페이지가 마련되어 있다.
<!-- source from url=(0038)http://www.ednkorea.com/jan04/df2.html -->
![]()
|
|
|
|

